Ensembling#
Ensembling in machine learning refers to the technique of combining multiple models to improve overall performance, accuracy, and robustness compared to using a single model. The idea is that individual models may make different errors, and by aggregating their predictions, the overall prediction can become more accurate.
Bagging (Bootstrap Aggregating)#
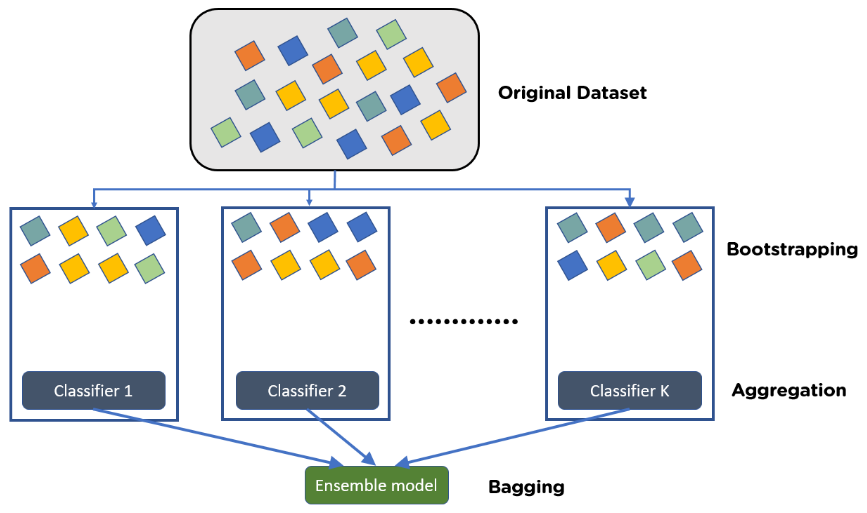
Multiple instances of the same model are trained on different subsets of the training data (usually created by random sampling with replacement).
Boosting#
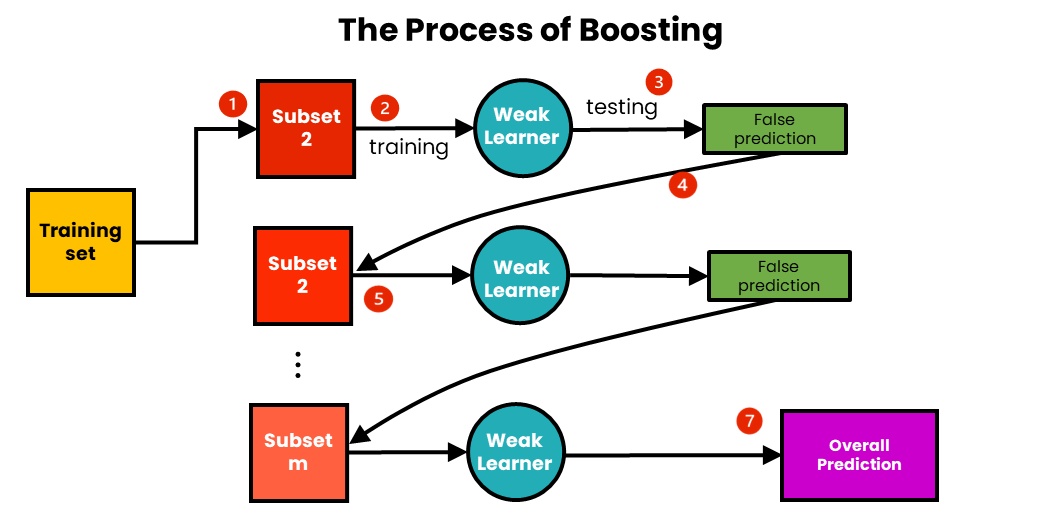
Models are trained sequentially, where each new model tries to correct the errors of the previous ones. This leads to an improvement in performance as weaker models are gradually refined.
Stacking#
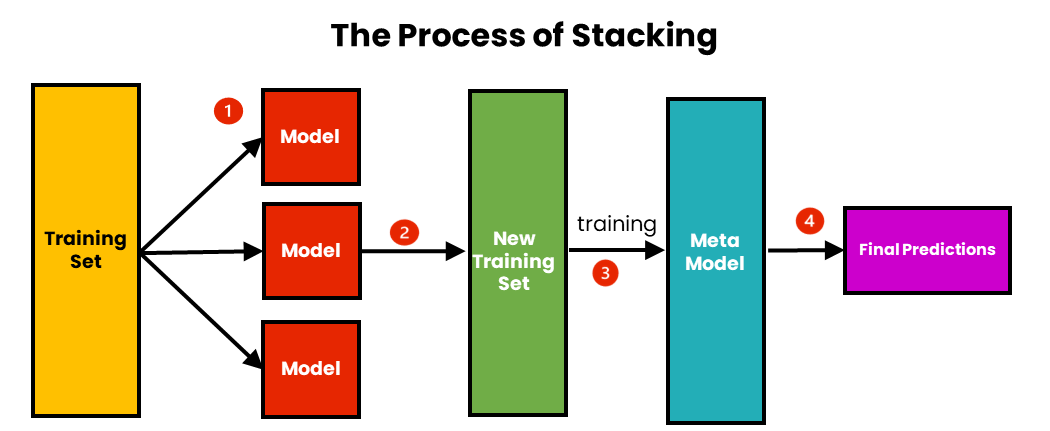
In stacking, multiple models are trained, and then their predictions are used as input to another model (often called a “meta-model”) which makes the final prediction.
Voting#

Simple ensembling method where multiple models make predictions, and the final prediction is made based on majority voting (for classification tasks) or averaging (for regression tasks).