Types of supervised learning#
Given a labeled training dataset
we want to build a predictive model \(f_{\boldsymbol \theta}\colon \mathbb R^d\to \mathcal Y\) which is usually taken from some parametric family
Dummy model
The simplest possible model is constant (dummy) model which always predicts the same value:
A dummy model has no parameters (\(m=0\)) and does not require any training.
To fit a model means to find a value of \(\boldsymbol \theta\) which minimizes the loss function
Depending on the set of targets \(\mathcal Y\) supervised learning is split into classification and regression.
Classification#
If \(\mathcal Y\) is a finite set of categories, the predictive model \(f_{\boldsymbol \theta}\colon \mathbb R^d\to \mathcal Y\) is often called a classifier. In should classify inputs into several categories from \(\mathcal Y\).
Binary classification#

In binary classification problems there are only two classes, which are often called positive and negative. The target set \(\mathcal Y\) in this case consists of two elements, and usually denoted as \(\mathcal Y = \{0, 1\}\) or \(\mathcal Y = \{-1, +1\}\).
Examples#
spam filtering (
1 = spam,0 = not spam)medical diagnosis (
1 = sick,0 = healthy)sentiment analysis (
1 = positive,0 = negative)credit card fraud detection (
1 = fraudulent transaction,0 = legitimate transaction)customer churn prediction (
1 = cutomer leaves,0 = customer stays)
Note
There’s no inherent rule that “positive” must correspond to a “good” outcome. Instead, it usually refers to the class of greater interest.
Loss function#
Let \(\widehat y_i = f_{\boldsymbol \theta}(\boldsymbol x_i)\) be the prediction of the model on the \(i\)-th sample. A typical loss function for binary classification is misclassification rate (or error rate) — the fraction of incorrect predictions (misclassifications):
The error rate is not a smooth function, that’s why a binary classifier often predicts a number \(\tilde y \in (0, 1)\) which is treated as probability of positive class. In such case binary cross-entropy loss is used:
Notation
By convention \(0\log 0 = 0\)
By default each \(\log\) has base \(e\)
Indicator \(\mathbb I[P]\) is defined as
Example
Suppose that true labels \(y\) and predictions \(\hat y\) are as follows:
\(y\) |
\(\hat y\) |
\(\tilde y\) |
|---|---|---|
\(0\) |
\(0\) |
\(0.2\) |
\(0\) |
\(1\) |
\(0.6\) |
\(1\) |
\(0\) |
\(0.3\) |
\(1\) |
\(1\) |
\(0.9\) |
\(0\) |
\(0\) |
\(0.1\) |
Calculate the missclassification rate (5) and the binary cross-entropy loss (6).
Solution
There are \(2\) misclassifications, hence, the error rate equals \(\frac 25 = 0.4\). For the cross entropy loss we have
Multiclass classification#
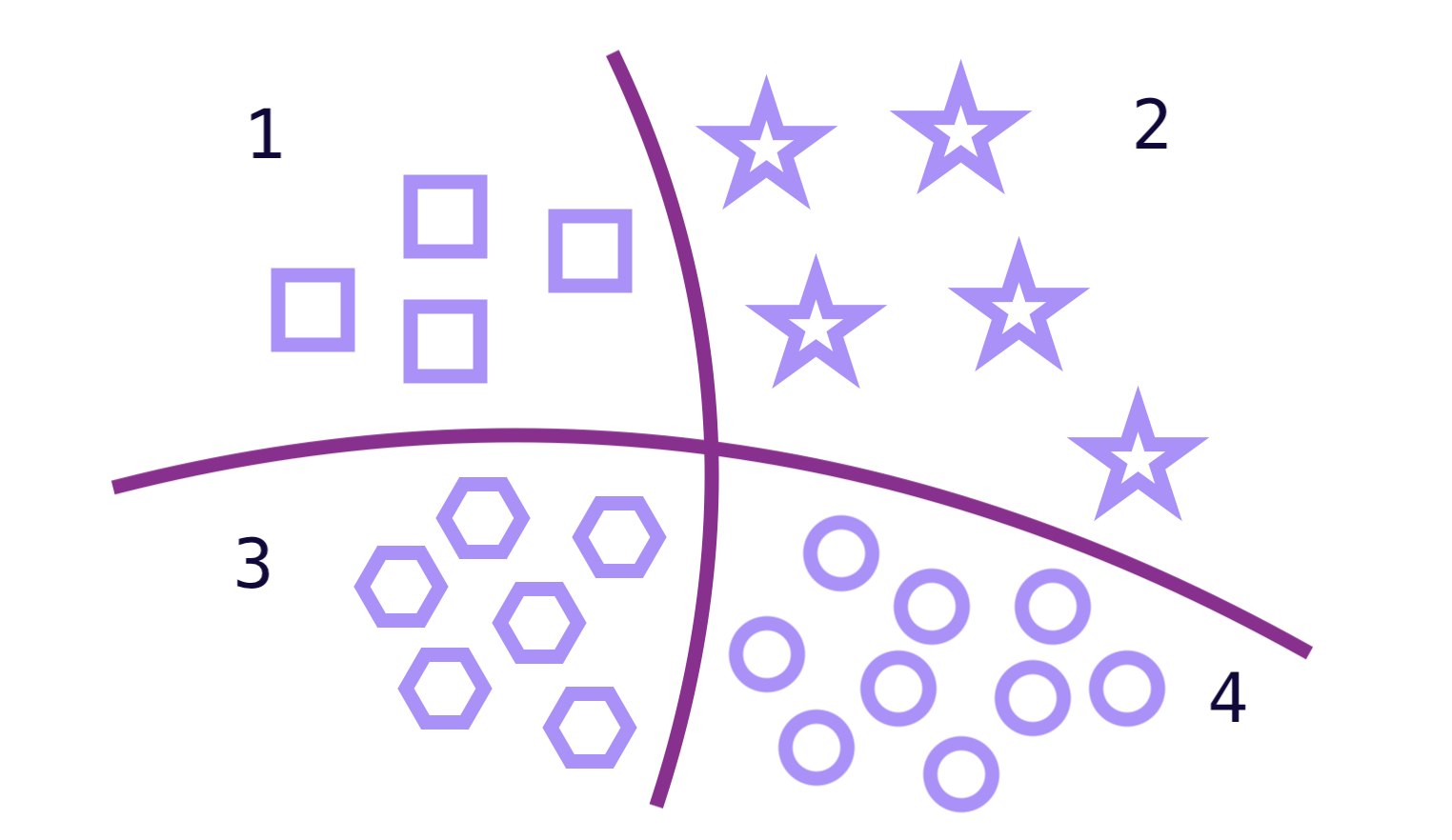
Quite often we need to categorize into several distance classes. Here are some examples:
image classificaton (e.g., MNIST)
language identification
music genre detection
The error rate (5) is still valid if we have more than two classes \(\mathcal Y = \{1, 2, \ldots, K\}\). More often, a multiclass variant of (6) is used.
After applying one-hot encoding targets become \(K\)-dimensional vectors:
Now suppose that a classifier predicts a vector of probabilities of belonging to class \(k\):
The cross-entropy loss is calculated as
Example
Classifying into \(3\) classes, model produces the following outputs:
\(y\) |
\(\boldsymbol {\hat y}\) |
|---|---|
\(0\) |
\((0.25, 0.4, 0.35)\) |
\(0\) |
\((0.5, 0.3, 0.2)\) |
\(1\) |
\(\big(\frac 12 - \frac 1{2\sqrt 2}, \frac 1{\sqrt 2}, \frac 12 - \frac 1{2\sqrt 2}\big)\) |
\(2\) |
\((0, 0, 1)\) |
Calculate the cross-entropy loss (7). Assume that log base is \(2\).
Regression#
If target set \(\mathcal Y\) is continuous (e.g., \(\mathcal Y = \mathbb R\) or \(\mathcal Y = \mathbb R^m\)) the predictive model \(f_{\boldsymbol \theta}\colon \mathbb R^d\to \mathcal Y\) is called a regression model or regressor.
The common choice for the loss on individual objects is quadratic loss
The overall loss function is obtained by averaging over the training dataset (4):
This loss is called mean squared error.
Linear regression#
If the function \(f_{\boldsymbol \theta}(\boldsymbol x_i) = \boldsymbol {\theta^\mathsf{T} x}_i + b\) is linear, then the model is called linear regression. In case of one feature this is just a linear function of a single variable
MSE loss equals to the average of sum of squares of the black line segments.
Exercises#
Suppose we have a dataset (4) with categorical targets \(\mathcal Y = \{1 ,\ldots, K\}\). Let \(n_k\) be the size of the \(k\)-th category:
\[ n_k = \sum\limits_{i=1}^n \mathbb I[y_i = k], \quad \sum\limits_{k=1}^K n_k = n. \]Consider a dummy model which always predicts category \(\ell\), \(1\leqslant \ell \leqslant K\). What is the value of the error rate (5)? For which \(\ell\) it is minimal?
The MSE for a constant model \(f_{\boldsymbol \theta}(\boldsymbol x_i) = c\) is given by
\[ \frac 1n \sum\limits_{i=1}^n (y_i - c)^2. \]For which \(c\) it is minimal?
How the answer to the previous problem will change if we replace MSE by MAE:
\[ \frac 1n \sum\limits_{i=1}^n \vert y_i - c\vert \to \min \limits_c \]How will the graph for linear regression look like in case of \(1\) or \(2\) points?