Data visualization#
# # для установки библиотек
# ! pip3 install seaborn
# ! pip3 install plotly
# ! pip3 install ggplot
# ! pip3 install matplotlib
# ! pip3 install matplotlib==3.0.0
#графики в svg выглядят более четкими
%config InlineBackend.figure_format = 'svg'
#увеличим дефолтный размер графиков
from pylab import rcParams
rcParams['figure.figsize'] = 10,5
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
Matplotlib#
xs = np.linspace(0, 2*np.pi, num=10)
plt.scatter(xs, np.sin(xs), c='r')
plt.axhline(c='k', alpha=0.75)
plt.axvline(c='k', alpha=0.75);

We’ll use Kaggle Video Games Dataset for visualizations.
df = pd.read_csv('Video_Games_Sales.csv.zip')
print(df.shape)
(16719, 16)
df.head()
| Name | Platform | Year_of_Release | Genre | Publisher | NA_Sales | EU_Sales | JP_Sales | Other_Sales | Global_Sales | Critic_Score | Critic_Count | User_Score | User_Count | Developer | Rating | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Wii Sports | Wii | 2006.0 | Sports | Nintendo | 41.36 | 28.96 | 3.77 | 8.45 | 82.53 | 76.0 | 51.0 | 8 | 322.0 | Nintendo | E |
| 1 | Super Mario Bros. | NES | 1985.0 | Platform | Nintendo | 29.08 | 3.58 | 6.81 | 0.77 | 40.24 | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | Mario Kart Wii | Wii | 2008.0 | Racing | Nintendo | 15.68 | 12.76 | 3.79 | 3.29 | 35.52 | 82.0 | 73.0 | 8.3 | 709.0 | Nintendo | E |
| 3 | Wii Sports Resort | Wii | 2009.0 | Sports | Nintendo | 15.61 | 10.93 | 3.28 | 2.95 | 32.77 | 80.0 | 73.0 | 8 | 192.0 | Nintendo | E |
| 4 | Pokemon Red/Pokemon Blue | GB | 1996.0 | Role-Playing | Nintendo | 11.27 | 8.89 | 10.22 | 1.00 | 31.37 | NaN | NaN | NaN | NaN | NaN | NaN |
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 16719 entries, 0 to 16718
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Name 16717 non-null object
1 Platform 16719 non-null object
2 Year_of_Release 16450 non-null float64
3 Genre 16717 non-null object
4 Publisher 16665 non-null object
5 NA_Sales 16719 non-null float64
6 EU_Sales 16719 non-null float64
7 JP_Sales 16719 non-null float64
8 Other_Sales 16719 non-null float64
9 Global_Sales 16719 non-null float64
10 Critic_Score 8137 non-null float64
11 Critic_Count 8137 non-null float64
12 User_Score 10015 non-null object
13 User_Count 7590 non-null float64
14 Developer 10096 non-null object
15 Rating 9950 non-null object
dtypes: float64(9), object(7)
memory usage: 2.0+ MB
df = df.dropna()
print(df.shape)
(6825, 16)
df.head()
| Name | Platform | Year_of_Release | Genre | Publisher | NA_Sales | EU_Sales | JP_Sales | Other_Sales | Global_Sales | Critic_Score | Critic_Count | User_Score | User_Count | Developer | Rating | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Wii Sports | Wii | 2006.0 | Sports | Nintendo | 41.36 | 28.96 | 3.77 | 8.45 | 82.53 | 76.0 | 51.0 | 8 | 322.0 | Nintendo | E |
| 2 | Mario Kart Wii | Wii | 2008.0 | Racing | Nintendo | 15.68 | 12.76 | 3.79 | 3.29 | 35.52 | 82.0 | 73.0 | 8.3 | 709.0 | Nintendo | E |
| 3 | Wii Sports Resort | Wii | 2009.0 | Sports | Nintendo | 15.61 | 10.93 | 3.28 | 2.95 | 32.77 | 80.0 | 73.0 | 8 | 192.0 | Nintendo | E |
| 6 | New Super Mario Bros. | DS | 2006.0 | Platform | Nintendo | 11.28 | 9.14 | 6.50 | 2.88 | 29.80 | 89.0 | 65.0 | 8.5 | 431.0 | Nintendo | E |
| 7 | Wii Play | Wii | 2006.0 | Misc | Nintendo | 13.96 | 9.18 | 2.93 | 2.84 | 28.92 | 58.0 | 41.0 | 6.6 | 129.0 | Nintendo | E |
df['User_Score'] = df.User_Score.astype('float64')
df['Year_of_Release'] = df.Year_of_Release.astype('int64')
df['User_Count'] = df.User_Count.astype('int64')
df['Critic_Count'] = df.Critic_Count.astype('int64')
useful_cols = ['Name', 'Platform', 'Year_of_Release', 'Genre',
'Global_Sales', 'Critic_Score', 'Critic_Count',
'User_Score', 'User_Count', 'Rating'
]
df[useful_cols].head(10)
| Name | Platform | Year_of_Release | Genre | Global_Sales | Critic_Score | Critic_Count | User_Score | User_Count | Rating | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Wii Sports | Wii | 2006 | Sports | 82.53 | 76.0 | 51 | 8.0 | 322 | E |
| 2 | Mario Kart Wii | Wii | 2008 | Racing | 35.52 | 82.0 | 73 | 8.3 | 709 | E |
| 3 | Wii Sports Resort | Wii | 2009 | Sports | 32.77 | 80.0 | 73 | 8.0 | 192 | E |
| 6 | New Super Mario Bros. | DS | 2006 | Platform | 29.80 | 89.0 | 65 | 8.5 | 431 | E |
| 7 | Wii Play | Wii | 2006 | Misc | 28.92 | 58.0 | 41 | 6.6 | 129 | E |
| 8 | New Super Mario Bros. Wii | Wii | 2009 | Platform | 28.32 | 87.0 | 80 | 8.4 | 594 | E |
| 11 | Mario Kart DS | DS | 2005 | Racing | 23.21 | 91.0 | 64 | 8.6 | 464 | E |
| 13 | Wii Fit | Wii | 2007 | Sports | 22.70 | 80.0 | 63 | 7.7 | 146 | E |
| 14 | Kinect Adventures! | X360 | 2010 | Misc | 21.81 | 61.0 | 45 | 6.3 | 106 | E |
| 15 | Wii Fit Plus | Wii | 2009 | Sports | 21.79 | 80.0 | 33 | 7.4 | 52 | E |
Начнем с самого простого и зачастую удобного способа визуализировать данные из pandas dataframe — это воспользоваться функцией plot.
Для примера построим график продаж видео игр в различных странах в зависимости от года. Для начала отфильтруем только нужные нам столбцы, затем посчитаем суммарные продажи по годам и у получившегося dataframe вызовем функцию plot без параметров.
В библиотеку pandas встроен wrapper для matplotlib.
[x for x in df.columns if 'Sales' in x]
['NA_Sales', 'EU_Sales', 'JP_Sales', 'Other_Sales', 'Global_Sales']
df1 = df[[x for x in df.columns if 'Sales' in x] + ['Year_of_Release']]\
.groupby('Year_of_Release').sum()
df1.head()
| NA_Sales | EU_Sales | JP_Sales | Other_Sales | Global_Sales | |
|---|---|---|---|---|---|
| Year_of_Release | |||||
| 1985 | 0.00 | 0.03 | 0.00 | 0.01 | 0.03 |
| 1988 | 0.00 | 0.02 | 0.00 | 0.01 | 0.03 |
| 1992 | 0.02 | 0.00 | 0.00 | 0.00 | 0.03 |
| 1994 | 0.39 | 0.26 | 0.53 | 0.08 | 1.27 |
| 1996 | 7.91 | 6.88 | 4.06 | 1.24 | 20.10 |
df1.plot();

В этом случае мы сконцентрировались на отображении трендов продаж в разных регионах.
C помощью параметра kind можно изменить тип графика, например, на bar chart. Matplotlib позволяет очень гибко настраивать графики. На графике можно изменить почти все, что угодно, но потребуется порыться в документации и найти нужные параметры. Например, параметра rot отвечает за угол наклона подписей к оси x.
df1.plot(kind='bar', rot=45, stacked=True);

Или можем сделать stacked bar chart, чтобы показать и динамику продаж и их разбиение по рынкам.
df1[list(filter(lambda x: x != 'Global_Sales', df1.columns))]\
.plot(kind='bar', rot=45, stacked=True);

df1[list(filter(lambda x: x != 'Global_Sales', df1.columns))]\
.plot(kind='area', rot=45);

Еще один часто встречающийся тип графиков - это гистограммы. Посмотрим на распределение оценок критиков.
df.Critic_Score.hist(bins=40);

ax = df.Critic_Score.hist()
ax.set_title('Critic Score distribution')
ax.set_xlabel('critic score')
ax.set_ylabel('games');

У гистограмм можно контролировать, на сколько групп мы разбиваем распределение с помощью параметра bins.
ax = df.Critic_Score.hist(bins=20)
ax.set_title('Critic Score distribution')
ax.set_xlabel('critic score')
ax.set_ylabel('games');

Еще немного познакомимся с тем, как в pandas можно стилизовать таблицы.
top_developers_df = df.groupby('Developer')[['Global_Sales']].sum()\
.sort_values('Global_Sales', ascending=False).head(10)
top_developers_df
| Global_Sales | |
|---|---|
| Developer | |
| Nintendo | 529.90 |
| EA Sports | 145.93 |
| EA Canada | 131.46 |
| Rockstar North | 119.47 |
| Capcom | 114.52 |
| Treyarch | 101.37 |
| Ubisoft Montreal | 101.24 |
| Ubisoft | 94.53 |
| EA Tiburon | 79.77 |
| Infinity Ward | 77.56 |
# ! pip3 install jinja2
top_developers_df.style.bar()
| Global_Sales | |
|---|---|
| Developer | |
| Nintendo | 529.900000 |
| EA Sports | 145.930000 |
| EA Canada | 131.460000 |
| Rockstar North | 119.470000 |
| Capcom | 114.520000 |
| Treyarch | 101.370000 |
| Ubisoft Montreal | 101.240000 |
| Ubisoft | 94.530000 |
| EA Tiburon | 79.770000 |
| Infinity Ward | 77.560000 |
with open('developers_rend.html', 'w') as f:
f.write(top_developers_df.style.bar().render())
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[23], line 2
1 with open('developers_rend.html', 'w') as f:
----> 2 f.write(top_developers_df.style.bar().render())
AttributeError: 'Styler' object has no attribute 'render'
Полезные ссылки#
Seaborn#
Теперь давайте перейдем к библиотеке seaborn. Seaborn — это по сути более высокоуровневое API на базе библиотеки matplotlib. Seaborn содержит более адекватные дефолтные настройки оформления графиков. Если просто добавить в код import seaborn, то картинки станут гораздо симпатичнее. Также в библиотеке есть достаточно сложные типы визуализации, которые в matplotlib потребовали бы большого количество кода.
Познакомимся с первым таким “сложным” типом графиков pair plot (scatter plot matrix). Эта визуализация поможет нам посмотреть на одной картинке, как связаны между собой различные признаки.
import seaborn as sns
# c svg pairplot браузер начинает тормозить
%config InlineBackend.figure_format = 'png'
sns_plot = sns.pairplot(
df[['Global_Sales', 'Critic_Score', 'User_Score']]);
sns_plot.savefig('pairplot.png')
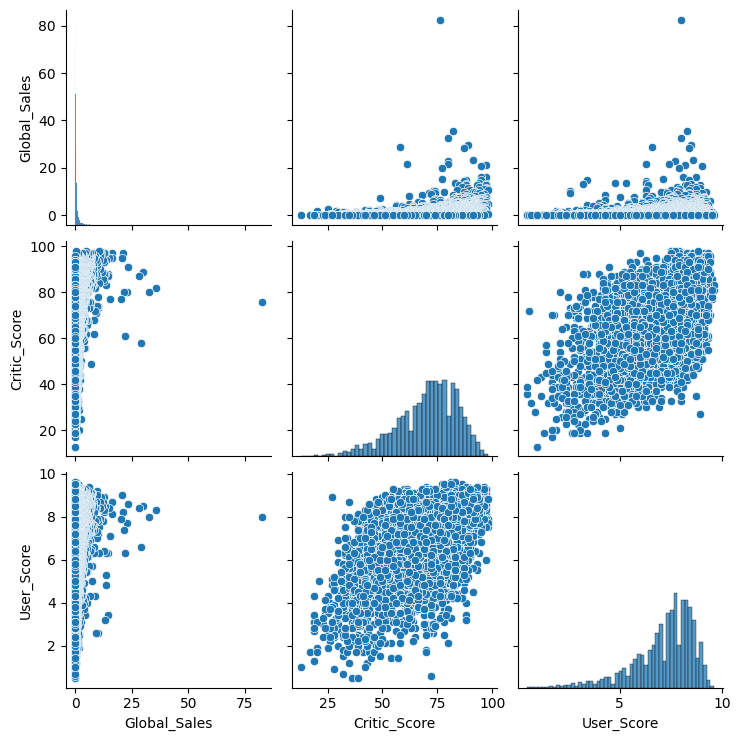
Также с помощью seaborn можно построить распределение, для примера посмотрим на распределение оценок критиков Critic_Score. Для этого построим distplot. По default’у на графике отображается гистограмма и kernel density estimation.
%config InlineBackend.figure_format = 'svg'
sns.distplot(df.Critic_Score);
/var/folders/_m/fd0pgt2d59q_98kq7r467pv80000gn/T/ipykernel_45625/1222772998.py:2: UserWarning:
`distplot` is a deprecated function and will be removed in seaborn v0.14.0.
Please adapt your code to use either `displot` (a figure-level function with
similar flexibility) or `histplot` (an axes-level function for histograms).
For a guide to updating your code to use the new functions, please see
https://gist.github.com/mwaskom/de44147ed2974457ad6372750bbe5751
sns.distplot(df.Critic_Score);

Для того чтобы подробнее посмотреть на взаимосвязь двух численных признаков, есть еще и joint_plot – это гибрид scatter plot и histogram (отображаются также гистограммы распределений признаков). Посмотрим на то, как связаны между собой оценка критиков Critic_Score и оценка пользователя User_Score.
sns.jointplot(x='Critic_Score', y='User_Score',
data=df, kind='scatter');

sns.jointplot(x='Critic_Score', y='User_Score',
data=df, kind='reg');

Box-and-Wisker Plot#
Еще один полезный тип графиков - это box plot. Давайте сравним пользовательские оценки игр для топ-5 крупнейших игровых платформ.
top_platforms = df.Platform.value_counts().sort_values(ascending = False).head(5)
top_platforms
Platform
PS2 1140
X360 858
PS3 769
PC 651
XB 565
Name: count, dtype: int64
sns.boxplot(x="Platform", y="Critic_Score",
data=df[df.Platform.isin(top_platforms.index.values)]);

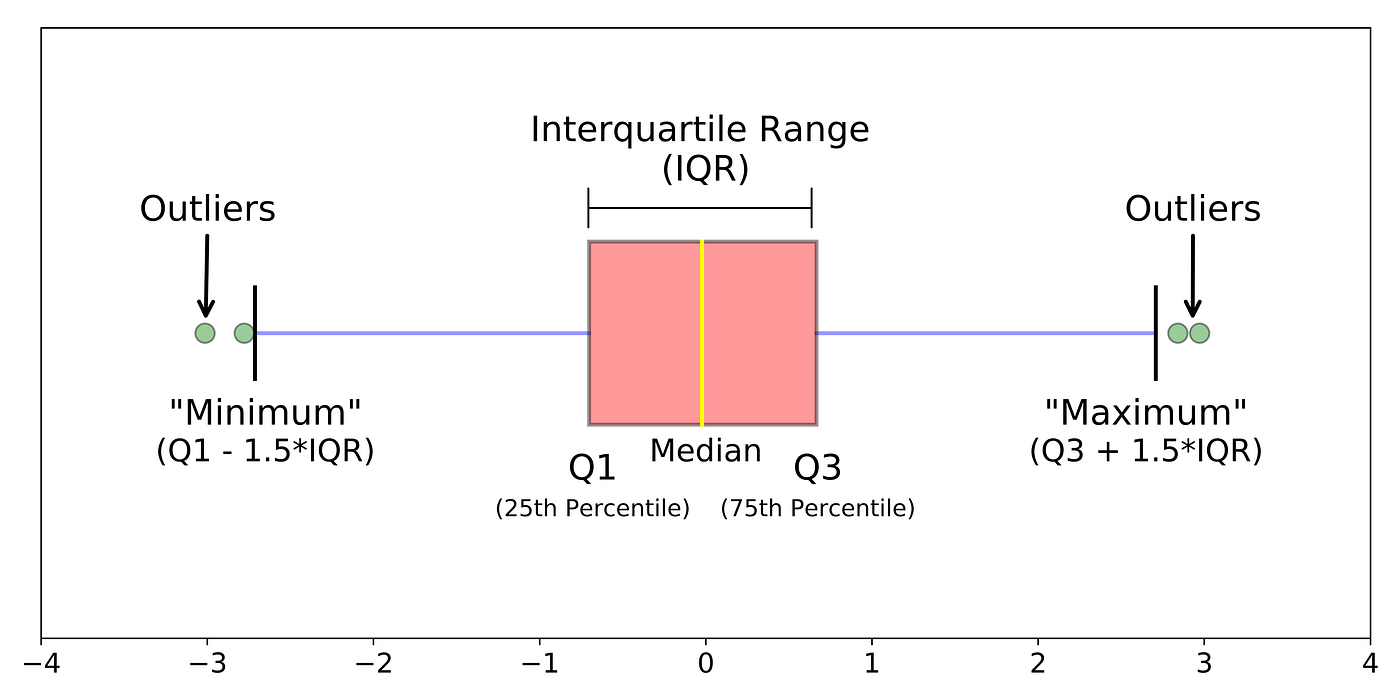
Box plot состоит из коробки (поэтому он и называется box plot), усиков и точек. Коробка показывает интерквантильный размах распределения, то есть соответственно 25% (Q1) и 75% (Q3) процентили. Черта внутри коробки обозначает медиану распределения.
С коробкой разобрались, перейдем к усам. Усы отображают весь разброс точек кроме выбросов, то есть минимальные и максимальные значения, которые попадают в промежуток (Q1 - 1.5*IQR, Q3 + 1.5*IQR), где IQR = Q3 - Q1 - интерквантильный размах. Точками на графике обозначаются выбросы (outliers) - те значения, которые не вписываются в промежуток значений, заданный усами графика.
И еще один тип графиков (последний из тех, которые мы рассмотрим в этой части) - это heat map. Heat map позволяет посмотреть на распределение какого-то численного признака по двум категориальным. Визуализируем суммарные продажи игр по жанрам и игровым платформам.
platform_genre_sales = df.pivot_table(
index='Platform',
columns='Genre',
values='Global_Sales',
aggfunc=sum).fillna(0).applymap(float)
platform_genre_sales
| Genre | Action | Adventure | Fighting | Misc | Platform | Puzzle | Racing | Role-Playing | Shooter | Simulation | Sports | Strategy |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Platform | ||||||||||||
| 3DS | 30.81 | 2.00 | 2.63 | 4.48 | 27.61 | 2.63 | 13.89 | 18.94 | 1.02 | 16.08 | 2.20 | 0.94 |
| DC | 0.00 | 1.33 | 0.56 | 0.00 | 0.12 | 0.00 | 0.20 | 0.68 | 0.05 | 0.52 | 1.09 | 0.00 |
| DS | 42.43 | 8.83 | 3.37 | 68.82 | 55.02 | 50.50 | 29.93 | 60.31 | 6.40 | 42.71 | 6.01 | 8.00 |
| GBA | 23.21 | 4.54 | 3.28 | 8.59 | 40.36 | 5.47 | 12.60 | 21.00 | 1.40 | 2.03 | 5.93 | 3.34 |
| GC | 29.99 | 4.56 | 15.81 | 12.72 | 24.67 | 3.31 | 11.09 | 12.48 | 13.04 | 8.39 | 19.91 | 3.45 |
| PC | 25.45 | 1.42 | 0.13 | 3.02 | 0.46 | 0.19 | 3.18 | 44.68 | 36.34 | 40.34 | 6.54 | 25.37 |
| PS | 54.93 | 1.10 | 18.91 | 5.66 | 18.92 | 0.26 | 34.17 | 44.07 | 5.86 | 1.67 | 20.75 | 0.25 |
| PS2 | 238.73 | 10.74 | 64.72 | 38.70 | 52.34 | 3.97 | 127.17 | 77.30 | 98.20 | 34.01 | 191.88 | 8.21 |
| PS3 | 262.38 | 16.18 | 47.83 | 26.59 | 20.91 | 0.40 | 62.17 | 64.00 | 174.54 | 7.91 | 98.20 | 3.19 |
| PS4 | 76.92 | 3.09 | 6.86 | 2.70 | 6.16 | 0.03 | 9.08 | 18.18 | 63.67 | 0.72 | 55.16 | 0.46 |
| PSP | 43.92 | 2.81 | 12.36 | 5.09 | 10.84 | 2.04 | 27.88 | 31.11 | 18.52 | 4.61 | 25.34 | 3.40 |
| PSV | 9.53 | 1.28 | 1.91 | 1.81 | 2.49 | 0.12 | 1.00 | 7.02 | 3.88 | 0.00 | 1.84 | 0.00 |
| Wii | 75.75 | 7.72 | 21.89 | 149.42 | 78.25 | 8.22 | 48.35 | 11.01 | 19.20 | 23.88 | 213.53 | 1.76 |
| WiiU | 13.61 | 0.08 | 1.22 | 10.93 | 21.33 | 1.30 | 7.09 | 1.26 | 5.56 | 0.20 | 2.39 | 1.11 |
| X360 | 209.90 | 11.52 | 35.30 | 70.09 | 10.26 | 0.36 | 56.14 | 68.62 | 260.35 | 13.02 | 109.74 | 8.00 |
| XB | 36.53 | 1.98 | 10.92 | 3.56 | 7.44 | 0.10 | 23.44 | 12.50 | 60.33 | 6.60 | 46.75 | 1.92 |
| XOne | 29.07 | 1.57 | 2.25 | 4.08 | 0.62 | 0.00 | 8.84 | 8.21 | 48.12 | 0.01 | 26.59 | 0.21 |
sns.heatmap(platform_genre_sales, annot=False, fmt=".1f", center = True);

Полезные ссылки#
Plotly#
Мы рассмотрели визуализации на базе библиотеки matplotlib. Однако, это не единственная опция для построения графиков на языке python. Познакомимся также с библиотекой plotly. Plotly - это open-source библиотека, которая позволяет строить интерактивные графики в jupyter.notebook’e без необходимости зарываться в javascript код.
Прелесть интерактивных графиков заключается в том, что можно посмотреть точное численное значение при наведении мыши, скрыть неинтересные ряды в визуализации, приблизить определенный участок графика и т.д.
Перед началом работы импортируем все необходимые модули и инициализируем plotly с помощью команды init_notebook_mode.
from plotly.offline import init_notebook_mode, iplot
import plotly.graph_objects as go
import plotly
import plotly.graph_objs as go
init_notebook_mode(connected=True)
Для начала построим line plot с динамикой числа вышедших игр и их продаж по годам.
global_sales_years_df = df.groupby('Year_of_Release')[['Global_Sales']].sum()
global_sales_years_df.head()
| Global_Sales | |
|---|---|
| Year_of_Release | |
| 1985 | 0.03 |
| 1988 | 0.03 |
| 1992 | 0.03 |
| 1994 | 1.27 |
| 1996 | 20.10 |
released_years_df = df.groupby('Year_of_Release')[['Name']].count()
released_years_df.head()
| Name | |
|---|---|
| Year_of_Release | |
| 1985 | 1 |
| 1988 | 1 |
| 1992 | 1 |
| 1994 | 1 |
| 1996 | 7 |
years_df = global_sales_years_df.join(released_years_df)
years_df.head()
| Global_Sales | Name | |
|---|---|---|
| Year_of_Release | ||
| 1985 | 0.03 | 1 |
| 1988 | 0.03 | 1 |
| 1992 | 0.03 | 1 |
| 1994 | 1.27 | 1 |
| 1996 | 20.10 | 7 |
years_df.columns = ['Global_Sales', 'Number_of_Games']
years_df.head()
| Global_Sales | Number_of_Games | |
|---|---|---|
| Year_of_Release | ||
| 1985 | 0.03 | 1 |
| 1988 | 0.03 | 1 |
| 1992 | 0.03 | 1 |
| 1994 | 1.27 | 1 |
| 1996 | 20.10 | 7 |
В plotly строится визуализация объекта Figure, который состоит из данных (массив линий, которые в библиотеке называются traces) и оформления/стиля, за который отвечает объект layout. В простых случаях можно вызывать функцию iplot и просто от массива traces.
trace0 = go.Scatter(
x=years_df.index,
y=years_df.Global_Sales,
name='Global Sales'
)
trace1 = go.Scatter(
x=years_df.index,
y=years_df.Number_of_Games,
name='Number of games released'
)
data = [trace0, trace1]
layout = {'title': 'Statistics of video games'}
fig = go.Figure(data=data, layout=layout)
#fig.show()
iplot(fig, show_link = False)
Также можно сразу сохранить график в виде html-файла.
# plotly.offline.plot(fig, filename='years_stats.html', show_link=False);
Посмотрим также на рыночную долю игровых платформ, расчитанную по количеству выпущенных игр и по суммарной выручке. Для этого построим bar chart.
global_sales_platforms_df = df.groupby('Platform')[['Global_Sales']].sum()
released_platforms_df = df.groupby('Platform')[['Name']].count()
platforms_df = global_sales_platforms_df.join(released_platforms_df)
platforms_df.columns = ['Global_Sales', 'Number_of_Games']
platforms_df.sort_values('Global_Sales', inplace=True)
platforms_df = platforms_df.apply(lambda x: 100*x/platforms_df.sum(), axis = 1)
platforms_df.head()
| Global_Sales | Number_of_Games | |
|---|---|---|
| Platform | ||
| DC | 0.085735 | 0.205128 |
| PSV | 0.581868 | 1.728938 |
| WiiU | 1.245136 | 1.304029 |
| 3DS | 2.322006 | 2.271062 |
| XOne | 2.441469 | 2.329670 |
trace0 = go.Bar(
x=platforms_df.index,
y=platforms_df.Global_Sales,
name='Global Sales',
orientation = 'v'
)
trace1 = go.Bar(
x=platforms_df.index,
y=platforms_df.Number_of_Games,
name='Number of games released',
orientation = 'v'
)
data = [trace0, trace1]
layout = {'title': 'Platforms share', 'xaxis': {'title': 'platform'}}
fig = go.Figure(data=data, layout=layout)
iplot(fig, show_link=False)
В plotly можно построить и box plot. Рассмотрим различия оценок критиков в зависимости от жанра игры.
df.Genre.unique()
array(['Sports', 'Racing', 'Platform', 'Misc', 'Action', 'Puzzle',
'Shooter', 'Fighting', 'Simulation', 'Role-Playing', 'Adventure',
'Strategy'], dtype=object)
data = []
for genre in df.Genre.unique():
data.append(
go.Box(y=df[df.Genre==genre].Critic_Score,
name=genre)
)
iplot(data, show_link = False)
Давайте посмотрим на график зависимости средней оценки пользователей и оценки критиков по жанрам. Это будет обычный scatter plot.
scores_genres_df = df.groupby('Genre')[['Critic_Score', 'User_Score']].mean()
sales_genres_df = df.groupby('Genre')[['Global_Sales']].sum()
genres_df = scores_genres_df.join(sales_genres_df)
genres_df.head()
| Critic_Score | User_Score | Global_Sales | |
|---|---|---|---|
| Genre | |||
| Action | 67.828834 | 7.095828 | 1203.16 |
| Adventure | 66.133065 | 7.160887 | 80.75 |
| Fighting | 69.732804 | 7.301852 | 249.95 |
| Misc | 67.460938 | 6.849740 | 416.26 |
| Platform | 70.000000 | 7.377171 | 377.80 |
trace0 = go.Scatter(
x=genres_df.Critic_Score,
y=genres_df.User_Score,
mode = 'markers'
)
data = [trace0]
layout = {'title': 'Statistics of video games genres', 'yaxis': {'title': 'user score'},
'xaxis': {'title': 'critic score'}}
fig = go.Figure(data=data, layout=layout)
iplot(fig, show_link=False)
Пока что ничего непонятно, давайте добавим к точкам подписи.
trace0 = go.Scatter(
x=genres_df.Critic_Score,
y=genres_df.User_Score,
mode = 'markers+text',
text = genres_df.index,
textposition='bottom center'
)
data = [trace0]
layout = {'title': 'Statistics of video games genres'}
fig = go.Figure(data=data, layout=layout)
iplot(fig, show_link=False)
Далее добавим на график еще одно измерение - размер жанра (суммарный объем продаж, который мы заранее посчитали) и получим bubble chart.
genres_df.index
Index(['Action', 'Adventure', 'Fighting', 'Misc', 'Platform', 'Puzzle',
'Racing', 'Role-Playing', 'Shooter', 'Simulation', 'Sports',
'Strategy'],
dtype='object', name='Genre')
trace0 = go.Scatter(
x=genres_df.Critic_Score,
y=genres_df.User_Score,
mode = 'markers+text',
text = genres_df.index,
#textposition='bottom',
marker = dict(
size = 1/10*genres_df.Global_Sales,
color = [
'aqua', 'azure', 'beige', 'lightgreen',
'lavender', 'lightblue', 'pink', 'salmon',
'wheat', 'ivory', 'silver'
]
)
)
data = [trace0]
layout = {
'title': 'Statistics of video games genres',
'xaxis': {'title': 'Critic Score'},
'yaxis': {'title': 'User Score'}
}
fig = go.Figure(data=data, layout=layout)
iplot(fig, show_link=False)
В plotly есть возможность делать графики в drop down menus, когда в зависимости от выбранного среза будут отображаться различные графики. Давайте построим гистораммы распределений оценок пользователей по жанрам.
traces = []
for genre in ['Racing', 'Shooter', 'Sports', 'Action']:
traces.append(
go.Histogram(
x=df[df.Genre == genre].User_Score,
histnorm='probability',
name = genre,
visible = (genre == 'Racing'))
)
layout = go.Layout(
title='User Score Distribution',
updatemenus=list([
dict(
x=-0.05,
y=1,
yanchor='top',
buttons=list([
dict(
args=['visible', [True] + [False]*3],
label='Racing',
method='restyle'
),
dict(
args=['visible', [False] + [True] + [False]*2],
label='Shooter',
method='restyle'
),
dict(
args=['visible', [False]*2 + [True] + [False]],
label='Sports',
method='restyle'
),
dict(
args=['visible', [False]*3 + [True]],
label='Action',
method='restyle'
)
]),
)
]),
)
fig = {'data': traces, 'layout': layout}
iplot(fig, show_link=False)
Полезные ссылки#
Plotly express#
Это обертка над plotly.graph_objects, которая позволяет строить графики проще.
import plotly.express as px
px.scatter(df, x= 'User_Score', y = 'Critic_Score')
px.scatter(df, x= 'User_Score', y = 'Critic_Score', color = 'Genre')
px.scatter(df, x= 'User_Score', y = 'Critic_Score',
marginal_y = 'histogram', marginal_x = 'histogram', trendline="ols")
px.scatter(df[df.Platform.isin(top_platforms)], x= 'User_Score', y = 'Critic_Score',
marginal_y = 'histogram', marginal_x = 'histogram', trendline="ols", facet_col = 'Platform')
px.scatter_matrix(df[['Global_Sales', 'Critic_Score', 'User_Score']])