Back propagation#
Outline:
Make the forward pass and calculate all hidden representations along with output and loss function:
Calculate the gradient of the loss function with respect to the output:
Make the backward pass from \(\boldsymbol X_{L-1}\) to \(\boldsymbol X_1\) and calculate \(\nabla_{\boldsymbol X_i}\mathcal L\), \(\nabla_{\boldsymbol W_i} \mathcal L\), \(\nabla_{\boldsymbol B_i}\mathcal L\) on each step
Backprop through one layer#
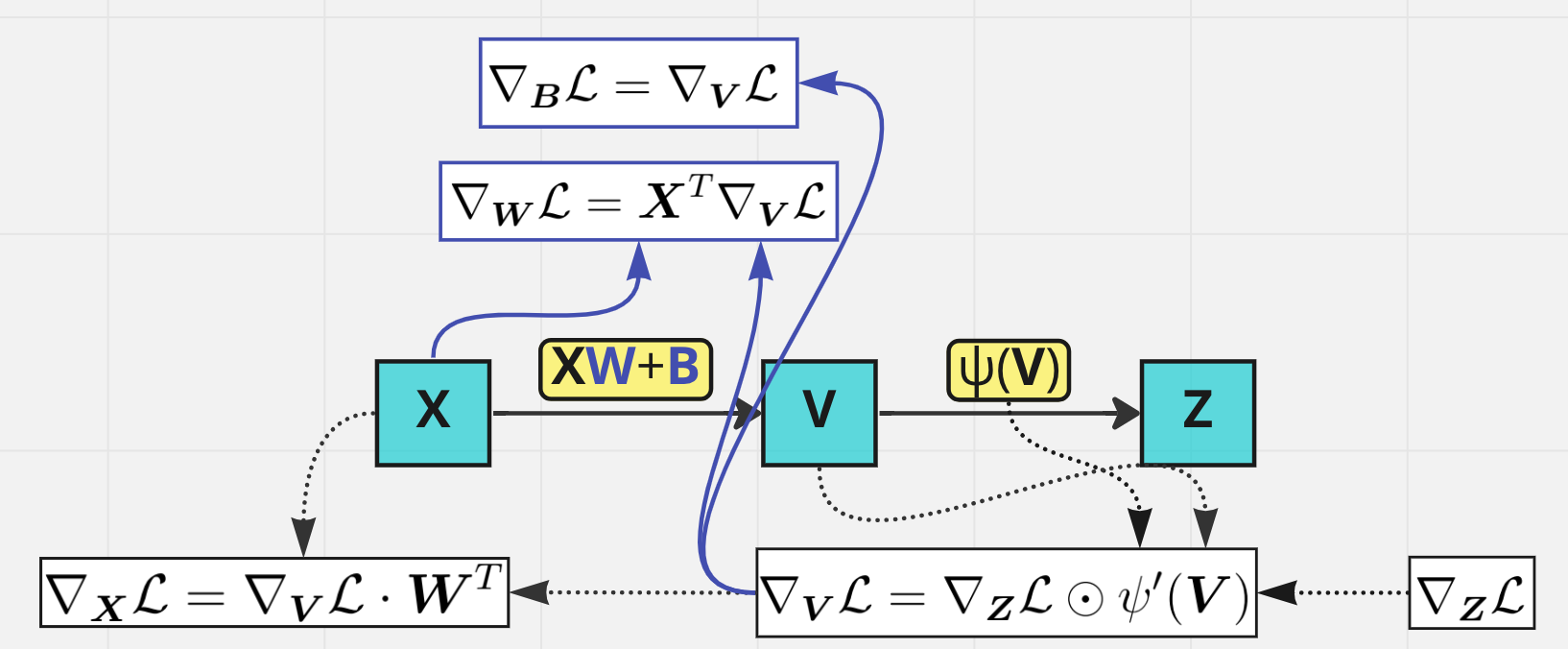
All you need is… chain rule!
Backprop through activation layer#
Suppose that we know the upstream gradient \(\nabla_{\boldsymbol Z}\mathcal L(\boldsymbol Z)\). The goal is to derive the formula for the downstream gradient \(\nabla_{\boldsymbol V}\tilde{\mathcal L}(\boldsymbol V)\) where \(\tilde{\mathcal L}(\boldsymbol V)=\mathcal L(\psi(\boldsymbol V))\). According to matrix calculus rules
From (67) we know that \(d \boldsymbol Z = d\psi(\boldsymbol V) = \psi'(\boldsymbol V) \odot d\boldsymbol V = d\boldsymbol V \odot \psi'(\boldsymbol V)\). Hence,
Exercise
Let \(\boldsymbol A, \boldsymbol B, \boldsymbol C \in \mathbb R^{m\times n}\). Show that
From this exercise we obtain
and \(\nabla_{\boldsymbol V}\tilde{\mathcal L}(\boldsymbol V) = \nabla \mathcal L(\boldsymbol Z) \odot \psi'(\boldsymbol V)\).
Backprop through linear layer#
Now our upstream gradient is \(\nabla_{\boldsymbol V}\mathcal L(\boldsymbol V)\), and we want to find the downstream gradient \(\nabla_{\boldsymbol X}\tilde{\mathcal L}(\boldsymbol X, \boldsymbol W, \boldsymbol B)\) where \(\tilde{\mathcal L}(\boldsymbol X, \boldsymbol W, \boldsymbol B)=\mathcal L(\boldsymbol{XW} + \boldsymbol B)\). Moreover, we also need formulas for \(\nabla_{\boldsymbol W}\tilde{\mathcal L}(\boldsymbol X, \boldsymbol W, \boldsymbol B)\) and \(\nabla_{\boldsymbol B}\tilde{\mathcal L}(\boldsymbol X, \boldsymbol W, \boldsymbol B)\) in order to make the gradient step.
Once again use chain rule and simple facts from calculus:
Hence,
Problem with bias
Usually bias is a vector, not matrix. If \(\boldsymbol X \in \mathbb R^{B\times m}\), \(\boldsymbol W \in \mathbb R^{m\times n}\) then bias is \(\boldsymbol b \in \mathbb R^{n}\), and linear layer looks like
Therefore, we want to find \(\nabla_{\boldsymbol b}\tilde{\mathcal L}\), which is also not matrix, but vector. It can be found from the equality
Denote
then
Since \(\mathrm{tr}(\boldsymbol a_i d\boldsymbol b^\mathsf{T}) = \mathrm{tr}(d\boldsymbol b^\mathsf{T}\boldsymbol a_i) = d\boldsymbol b^\mathsf{T}\boldsymbol a_i = \boldsymbol a_i^\mathsf{T}d\boldsymbol b\), we finally get
Hence, the downstream gradient \(\nabla\tilde{\mathcal L}(\boldsymbol b)\) is equal to the sum of the rows of the upstream gradient \(\nabla \mathcal L(\boldsymbol V)\).
Backprop through loss function#
Regression#
The most common choice for (multiple) regression is MSE: if target is \(\boldsymbol Y \in \mathbb R^{B\times m}\), model output is \(\widehat{\boldsymbol Y} \in \mathbb R^{B\times m}\), then
Since \(\Vert \boldsymbol Y - \widehat{\boldsymbol Y}\Vert_F^2 = \mathrm{tr}\big((\boldsymbol Y - \widehat{\boldsymbol Y})^\mathsf{T}(\boldsymbol Y - \widehat{\boldsymbol Y})\big)\),
Consequently,
Sometimes they use sum of squares instead of MSE, then the multiplier \(\frac 1{Bm}\) is omitted.
Classification#
The usual choice of loss here is cross-entropy loss:
The target matrix \(\boldsymbol Y \in \mathbb R^{B\times K}\) consists of one-hot encoded rows, each of which contains \(1\) one and \(K-1\) zeros. Each row of the prediction matrix \(\boldsymbol {\widehat Y} \in \mathbb R^{B\times K}\) must be a valid probability distribution, which is achived by applying Softmax:
Формально Softmax и кросс-энтропия — это два подряд идущих слоя, однако, на практике в целях повышения вычислительной стабильности их часто объединяют в один (например, в pytorch Softmax и поэлементное взятие логарифма объединены в один слой LogSoftmax).
Plugging (38) into (37), we obtain
Now differentiate it with respect to \(X_{mn}\):
where \(\delta_{ij}\) is Kronecker delta. Since target matrix \(\boldsymbol Y\) enjoys the property \(\sum\limits_{j=1}^K Y_{ij} = 1\) for all \(i=1,\ldots, B\), we get
Hence,