Probabilistic models for linear regression#
Consider a regression problem with dataset \(\mathcal D = \{(\boldsymbol x_i, y_i)\}_{i=1}^n\), \(y_i\in\mathbb R\). The probabilistic model for the linear regression model assumes that
where \(\varepsilon_i\) is some random noise.
Gaussian model#
In this setting the random noise is gaussian: \(\varepsilon_i \sim \mathcal N (0, \sigma^2)\). Hence,
Q. What is \(\mathbb E y_i\)? \(\mathbb V y_i\)?
A picture from ML Handbook:
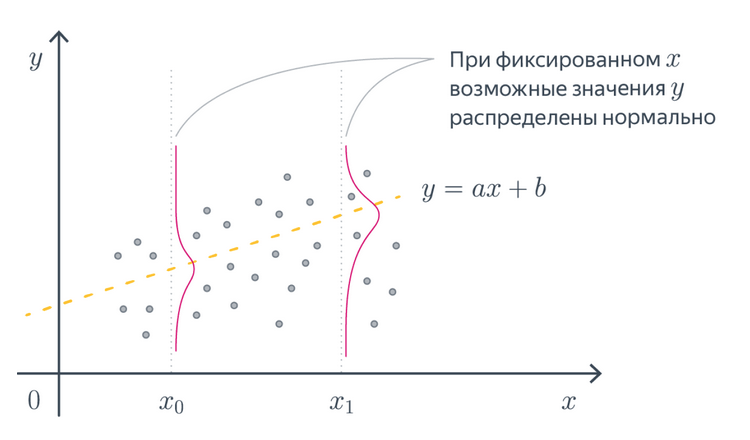
Q. What is \(\boldsymbol x_i\) and \(\boldsymbol w\) in this picture?
The likelihood of the dataset \(\mathcal D\) is
Hence, the negative log-likelihood is
Q. How does this NLL relates to the loss function (21) of the linear regression model?
Thus, the optimal weights (23) of the linear regression with MSE loss coincide with MLE:
Q. Let \(\sigma\) be also a learnable parameter. What is MLE \(\widehat \sigma^2\) for it?
Laplacian model#
Now suppose that our loss function is MAE. Then
Which probabilistic model will give
Well, then likelihood should be
Hence,
and
Bayesian linear regression#
Gaussian prior#
Let prior distribution be Gaussian:
Then posterior distribution
is also Gaussian.
Example
Let \(y = ax\) be 1-d linear regression model and \(p(a) = \mathcal N(0, \tau^2)\). Find posterior \(p(a \vert \boldsymbol x, \boldsymbol y)\) after observing a dataset \(\{(x_i, y_i)\}_{i=1}^n\).
Possible answer
To find \(\boldsymbol {\widehat w}_{\mathrm{MAP}}\), we need to maximize posterior \(p(\boldsymbol w \vert \boldsymbol X, \boldsymbol y)\). This is the same as to minimize
Recall that \(p( \boldsymbol y \vert \boldsymbol X, \boldsymbol w) = \mathcal N(\boldsymbol y \vert \boldsymbol{Xw}, \sigma^2 \boldsymbol I)\). According to calculations from ML Handbook
Hence,
Can you recognize the objective of the ridge regression with \(C = \frac{\sigma^2}{\tau^2}\)? The analytical solution is
Contnuing calculations, we can find posterior:
Laplacian prior#
Consinder the following prior: \(w_1, \ldots, w_d\) are i.i.d laplacian random variables with parameter \(\lambda\). Then
The likelihood \(p( \boldsymbol y \vert \boldsymbol X, \boldsymbol w)\) is still \(\mathcal N(\boldsymbol{Xw}, \sigma^2 \boldsymbol I)\). Then
Hence, maximum a posteriori estimation is
This is exactly the objective of LASSO.