Reinforcement Learning#
A lot of RL resources are collected here.
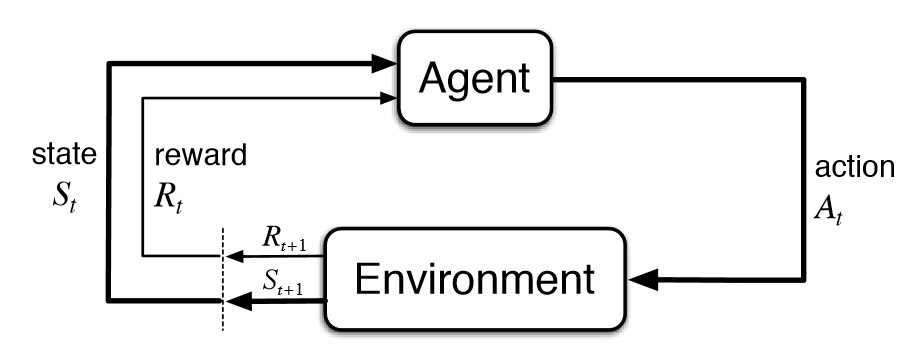
Reinforcement Learning (RL) is a type of machine learning where an agent learns to make decisions by interacting with an environment. The agent learns through trial and error, receiving rewards or penalties for its actions.
Core Components#
States#
The state \(s \in \mathcal{S}\) represents the current situation of the environment. It contains all relevant information the agent needs to make decisions.
Examples:
Chess: Current position of all pieces on the board
Self-driving car: Position, speed, direction, and sensor readings
Stock trading: Current prices, market indicators, and portfolio status
Actions#
Actions \(a \in \mathcal{A}\) are the possible moves or decisions an agent can make in a given state.
Examples:
Robot navigation: {move_forward, turn_left, turn_right, stop}
Game of Pong: {move_up, move_down, stay}
Thermostat control: {increase_temp, decrease_temp, maintain}
Rewards#
The reward \(r\) is a scalar feedback signal that indicates how good or bad the agent’s action was. It’s the primary learning signal in RL.
The cumulative reward (return) \(G_t\) from timestep \(t\) is defined as:
Examples:
Game scoring: +1 for winning, -1 for losing, 0 for other moves
Energy optimization: -\((\text{energy_cost} + \text{comfort_deviation})\)
Robot navigation: -1 for collisions, +10 for reaching goal, -0.1 per step
Discount Factor \(\gamma\)#
The discount factor γ (gamma) determines how much the agent values future rewards compared to immediate ones:
\(\gamma = 0\): “Myopic” agent only considers immediate rewards
\(\gamma = 1\): “Far-sighted” agent values future rewards almost as much as immediate ones
Exercise
A robot is navigating through a maze and receives the following sequence of rewards:
Time Step |
\(t_0\) |
\(t_1\) |
\(t_2\) |
\(t_3\) |
\(t_4\) |
|---|---|---|---|---|---|
Reward |
\(-1\) |
\(-1\) |
\(-1\) |
\(-1\) |
\(+10\) |
Calculate the cumulative reward \(G_0\) starting from \(t_0\) for the following discount factors:
\(\gamma = 0\) (Only immediate rewards)
\(\gamma = 0.5\) (Moderate discounting)
\(\gamma = 0.9\) (Small discounting)
\(\gamma = 1.0\) (No discounting)
Main goal of RL
The main goal of reinforcement learning is to learn a policy \(\pi: \mathcal{S} \to \mathcal{A}\) that maximizes the expected cumulative reward over time:
Note that a policy can be deterministic or stochastic. In the latter case, the policy is a distribution over actions: \(\pi(a|s) = \mathbb{P}[A_t = a | S_t = s]\).