CNN Architectures#
See here for a short list.
This guide explores the most influential CNN architectures that revolutionized computer vision. We’ll cover their key innovations, architectures, and impacts on the field.
1. LeNet-5 (1998)#

LeNet-5 was pioneered by Yann LeCun and was primarily used for digit recognition (MNIST dataset).
Key Features:#
7 layers (not counting input)
Convolutional layers followed by average pooling
Approximately 60K parameters
First successful application of CNNs
Input size: 32×32 pixels
2. AlexNet (2012)#
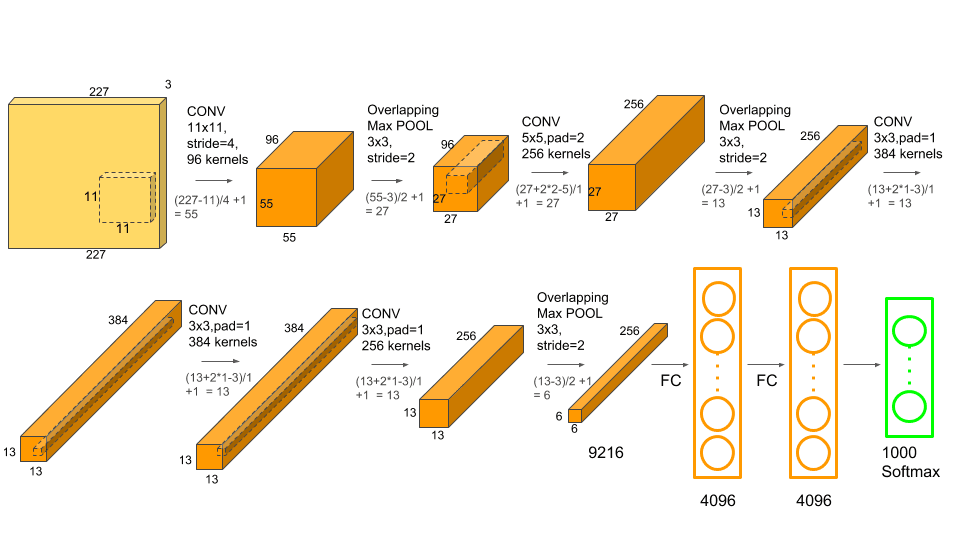
AlexNet marked the beginning of the deep learning revolution by winning the 2012 ImageNet competition.
Key Innovations:#
First use of ReLU activation function in CNNs
Dropout for regularization (0.5)
Data augmentation techniques
Local Response Normalization (LRN)
Training on multiple GPUs
Architecture Details:#
8 layers (5 convolutional, 3 fully connected)
60 million parameters
Input size: 227×227×3
Max pooling layers
Final 1000-way softmax
3. VGG16/VGG19 (2014)#

VGG networks demonstrated that depth is crucial for good performance. They used a very uniform architecture with small 3×3 filters throughout.
Key Features:#
Uniform architecture with 3×3 convolutions
Deep network (16-19 layers)
2×2 max pooling
Three fully connected layers at the end
138M parameters (VGG16)
Architecture Pattern:#
Multiple 3×3 conv layers + ReLU
Max pooling to reduce spatial dimensions
Double the number of filters after pooling
Final dense layers: 4096 → 4096 → 1000
4. GoogLeNet/Inception (2014)#
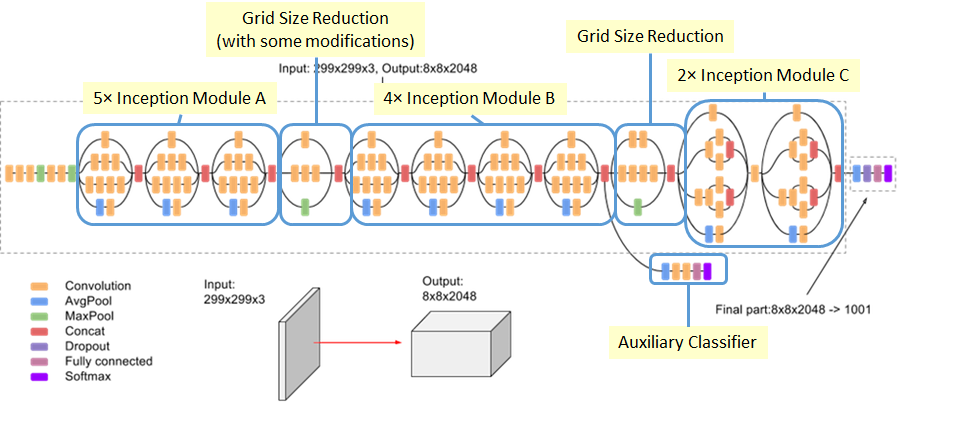
GoogLeNet introduced the Inception module, which processes input in parallel through different filter sizes.
Key Innovations:#
Inception modules with parallel convolutions
1×1 convolutions for dimension reduction
Global average pooling instead of dense layers
Auxiliary classifiers during training
Only 6.8M parameters (much less than VGG)
Inception Module Structure:#
1×1 convolutions
1×1 followed by 3×3 convolutions
1×1 followed by 5×5 convolutions
3×3 max pooling followed by 1×1 convolutions
5. ResNet (2015)#

ResNet solved the degradation problem in very deep networks using skip connections (residual learning).
Key Innovations:#
Residual connections (skip connections)
Batch normalization after each convolution
No fully connected layers except final classifier
Deep architectures (up to 152 layers)
Identity mappings in deep residual networks
Architecture Details:#
Multiple variants (ResNet-18, 34, 50, 101, 152)
Bottleneck blocks in deeper networks
25.6 million parameters (ResNet-50)
Comparison Table#
Architecture |
Year |
Layers |
Parameters |
Top-1 Accuracy (ImageNet) |
Top-5 Accuracy (ImageNet) |
Key Innovation |
|---|---|---|---|---|---|---|
LeNet-5 |
1998 |
7 |
60K |
N/A |
N/A |
First successful CNN |
AlexNet |
2012 |
8 |
60M |
63.3% |
84.7% |
ReLU, Dropout |
VGG16 |
2014 |
16 |
138M |
71.5% |
92.7% |
Uniform 3×3 conv |
GoogLeNet |
2014 |
22 |
6.8M |
74.8% |
93.3% |
Inception modules |
ResNet-50 |
2015 |
50 |
25.6M |
76.0% |
96.4% |
Residual connections |
Modern Trends#
Recent developments in CNN architectures:
EfficientNet (2019)
Compound scaling of depth/width/resolution
Better accuracy with fewer parameters
Systematic network scaling
Vision Transformers (2020)
Adapting transformer architecture to vision
Competitive with CNNs on large datasets
Potential to replace CNNs in some tasks
MobileNet (2017-2019)
Depthwise separable convolutions
Designed for mobile devices
Efficient inference on edge devices
RegNet (2020)
Systematic network design
Optimized performance-computation trade-off
Data-driven design decisions
References#
LeCun, Y., et al. (1998). Gradient-based learning applied to document recognition
Krizhevsky, A., et al. (2012). ImageNet Classification with Deep CNNs
Simonyan, K., & Zisserman, A. (2014). Very Deep Convolutional Networks
Szegedy, C., et al. (2015). Going Deeper with Convolutions
He, K., et al. (2016). Deep Residual Learning for Image Recognition </rewritten_file>