Regression tree#
A regression tree is a type of decision tree used for solving regression problems. Regression problems involve predicting a continuous target variable, as opposed to classification problems where the goal is to predict discrete class labels. Regression trees are a popular machine learning technique for modeling relationships between input features and continuous outcomes.
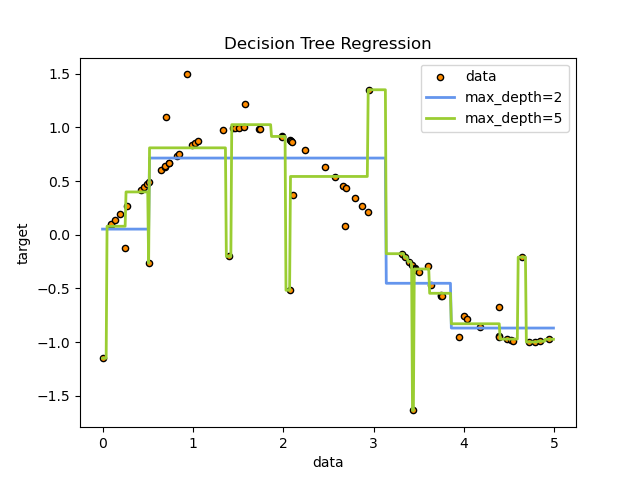
Example: Boston dataset#
import pandas as pd
boston = pd.read_csv("../ISLP_datasets/Boston.csv").drop("Unnamed: 0", axis=1)
boston.head()
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
Cell In[1], line 2
1 import pandas as pd
----> 2 boston = pd.read_csv("../ISLP_datasets/Boston.csv").drop("Unnamed: 0", axis=1)
3 boston.head()
File /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages/pandas/io/parsers/readers.py:912, in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, date_format, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, encoding_errors, dialect, on_bad_lines, delim_whitespace, low_memory, memory_map, float_precision, storage_options, dtype_backend)
899 kwds_defaults = _refine_defaults_read(
900 dialect,
901 delimiter,
(...)
908 dtype_backend=dtype_backend,
909 )
910 kwds.update(kwds_defaults)
--> 912 return _read(filepath_or_buffer, kwds)
File /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages/pandas/io/parsers/readers.py:577, in _read(filepath_or_buffer, kwds)
574 _validate_names(kwds.get("names", None))
576 # Create the parser.
--> 577 parser = TextFileReader(filepath_or_buffer, **kwds)
579 if chunksize or iterator:
580 return parser
File /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages/pandas/io/parsers/readers.py:1407, in TextFileReader.__init__(self, f, engine, **kwds)
1404 self.options["has_index_names"] = kwds["has_index_names"]
1406 self.handles: IOHandles | None = None
-> 1407 self._engine = self._make_engine(f, self.engine)
File /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages/pandas/io/parsers/readers.py:1661, in TextFileReader._make_engine(self, f, engine)
1659 if "b" not in mode:
1660 mode += "b"
-> 1661 self.handles = get_handle(
1662 f,
1663 mode,
1664 encoding=self.options.get("encoding", None),
1665 compression=self.options.get("compression", None),
1666 memory_map=self.options.get("memory_map", False),
1667 is_text=is_text,
1668 errors=self.options.get("encoding_errors", "strict"),
1669 storage_options=self.options.get("storage_options", None),
1670 )
1671 assert self.handles is not None
1672 f = self.handles.handle
File /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages/pandas/io/common.py:859, in get_handle(path_or_buf, mode, encoding, compression, memory_map, is_text, errors, storage_options)
854 elif isinstance(handle, str):
855 # Check whether the filename is to be opened in binary mode.
856 # Binary mode does not support 'encoding' and 'newline'.
857 if ioargs.encoding and "b" not in ioargs.mode:
858 # Encoding
--> 859 handle = open(
860 handle,
861 ioargs.mode,
862 encoding=ioargs.encoding,
863 errors=errors,
864 newline="",
865 )
866 else:
867 # Binary mode
868 handle = open(handle, ioargs.mode)
FileNotFoundError: [Errno 2] No such file or directory: '../ISLP_datasets/Boston.csv'
Select features and targets:
y = boston['medv']
X = boston.drop('medv', axis=1)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[2], line 1
----> 1 y = boston['medv']
2 X = boston.drop('medv', axis=1)
NameError: name 'boston' is not defined
Split into train and test:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[3], line 3
1 from sklearn.model_selection import train_test_split
----> 3 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
NameError: name 'X' is not defined
Train a regression decision tree:
from sklearn.tree import DecisionTreeRegressor, plot_tree, export_graphviz
DT = DecisionTreeRegressor()
DT.fit(X_train, y_train)
print("Train R-score:", DT.score(X_train, y_train))
print("Test R-score:", DT.score(X_test, y_test))
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[4], line 4
1 from sklearn.tree import DecisionTreeRegressor, plot_tree, export_graphviz
3 DT = DecisionTreeRegressor()
----> 4 DT.fit(X_train, y_train)
5 print("Train R-score:", DT.score(X_train, y_train))
6 print("Test R-score:", DT.score(X_test, y_test))
NameError: name 'X_train' is not defined
The tree is quite deep:
plot_tree(DT, filled=True);
---------------------------------------------------------------------------
NotFittedError Traceback (most recent call last)
Cell In[5], line 1
----> 1 plot_tree(DT, filled=True);
File /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages/sklearn/utils/_param_validation.py:211, in validate_params.<locals>.decorator.<locals>.wrapper(*args, **kwargs)
205 try:
206 with config_context(
207 skip_parameter_validation=(
208 prefer_skip_nested_validation or global_skip_validation
209 )
210 ):
--> 211 return func(*args, **kwargs)
212 except InvalidParameterError as e:
213 # When the function is just a wrapper around an estimator, we allow
214 # the function to delegate validation to the estimator, but we replace
215 # the name of the estimator by the name of the function in the error
216 # message to avoid confusion.
217 msg = re.sub(
218 r"parameter of \w+ must be",
219 f"parameter of {func.__qualname__} must be",
220 str(e),
221 )
File /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages/sklearn/tree/_export.py:196, in plot_tree(decision_tree, max_depth, feature_names, class_names, label, filled, impurity, node_ids, proportion, rounded, precision, ax, fontsize)
77 @validate_params(
78 {
79 "decision_tree": [DecisionTreeClassifier, DecisionTreeRegressor],
(...)
109 fontsize=None,
110 ):
111 """Plot a decision tree.
112
113 The sample counts that are shown are weighted with any sample_weights that
(...)
193 [...]
194 """
--> 196 check_is_fitted(decision_tree)
198 exporter = _MPLTreeExporter(
199 max_depth=max_depth,
200 feature_names=feature_names,
(...)
209 fontsize=fontsize,
210 )
211 return exporter.export(decision_tree, ax=ax)
File /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages/sklearn/utils/validation.py:1462, in check_is_fitted(estimator, attributes, msg, all_or_any)
1459 raise TypeError("%s is not an estimator instance." % (estimator))
1461 if not _is_fitted(estimator, attributes, all_or_any):
-> 1462 raise NotFittedError(msg % {"name": type(estimator).__name__})
NotFittedError: This DecisionTreeRegressor instance is not fitted yet. Call 'fit' with appropriate arguments before using this estimator.
Let’s limit its depth:
DT = DecisionTreeRegressor(max_depth=5)
DT.fit(X_train, y_train)
print("Train R-score:", DT.score(X_train, y_train))
print("Test R-score:", DT.score(X_test, y_test))
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[6], line 2
1 DT = DecisionTreeRegressor(max_depth=5)
----> 2 DT.fit(X_train, y_train)
3 print("Train R-score:", DT.score(X_train, y_train))
4 print("Test R-score:", DT.score(X_test, y_test))
NameError: name 'X_train' is not defined
plot_tree(DT, filled=True);
---------------------------------------------------------------------------
NotFittedError Traceback (most recent call last)
Cell In[7], line 1
----> 1 plot_tree(DT, filled=True);
File /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages/sklearn/utils/_param_validation.py:211, in validate_params.<locals>.decorator.<locals>.wrapper(*args, **kwargs)
205 try:
206 with config_context(
207 skip_parameter_validation=(
208 prefer_skip_nested_validation or global_skip_validation
209 )
210 ):
--> 211 return func(*args, **kwargs)
212 except InvalidParameterError as e:
213 # When the function is just a wrapper around an estimator, we allow
214 # the function to delegate validation to the estimator, but we replace
215 # the name of the estimator by the name of the function in the error
216 # message to avoid confusion.
217 msg = re.sub(
218 r"parameter of \w+ must be",
219 f"parameter of {func.__qualname__} must be",
220 str(e),
221 )
File /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages/sklearn/tree/_export.py:196, in plot_tree(decision_tree, max_depth, feature_names, class_names, label, filled, impurity, node_ids, proportion, rounded, precision, ax, fontsize)
77 @validate_params(
78 {
79 "decision_tree": [DecisionTreeClassifier, DecisionTreeRegressor],
(...)
109 fontsize=None,
110 ):
111 """Plot a decision tree.
112
113 The sample counts that are shown are weighted with any sample_weights that
(...)
193 [...]
194 """
--> 196 check_is_fitted(decision_tree)
198 exporter = _MPLTreeExporter(
199 max_depth=max_depth,
200 feature_names=feature_names,
(...)
209 fontsize=fontsize,
210 )
211 return exporter.export(decision_tree, ax=ax)
File /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages/sklearn/utils/validation.py:1462, in check_is_fitted(estimator, attributes, msg, all_or_any)
1459 raise TypeError("%s is not an estimator instance." % (estimator))
1461 if not _is_fitted(estimator, attributes, all_or_any):
-> 1462 raise NotFittedError(msg % {"name": type(estimator).__name__})
NotFittedError: This DecisionTreeRegressor instance is not fitted yet. Call 'fit' with appropriate arguments before using this estimator.
import graphviz
dot_data = export_graphviz(DT, out_file=None,
feature_names=boston.columns[:-1],
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[8], line 4
1 import graphviz
3 dot_data = export_graphviz(DT, out_file=None,
----> 4 feature_names=boston.columns[:-1],
5 filled=True, rounded=True,
6 special_characters=True)
7 graph = graphviz.Source(dot_data)
8 graph
NameError: name 'boston' is not defined